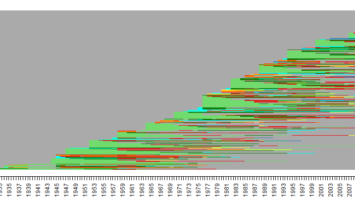
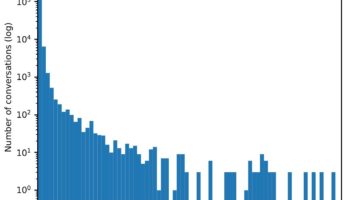
The FOPPA database (French Open Public Procurement Award notices) is a database constituted in the framework of the ANR DeCoMaP project (ANR-19-CE38-0004). It contains public procurement notices published in France from 2010 to 2020. It relies on a subset of the TED database (Tenders Electronic Daily, an appendix of the EU official bulletin). These data have a number of issues, the most serious being that the unique ID of most involved agents are missing. We performed a number of operations to solve these issues and obtain a usable database. These operations and their outcomes are described in detail in the below technical report. Production date: 2019–2024 Publicly available database: 10.5281/zenodo.7433154 Source code used to build the base: https://github.com/CompNet/FoppaInit/ Technical report explaining the processing: Lucas Potin, Vincent Labatut, Rosa Figueiredo, Christine Largeron, Pierre-Henri Morand. FOPPA: A database of French Open Public Procurement Award notices. Technical Report, Avignon Université. 2022. ⟨hal-03796734⟩ Data paper describing the database (cite this paper if you use these data): Lucas Potin, Vincent Labatut, Pierre-Henri Morand, Christine Largeron. FOPPA: an open database of French public procurement award notices from 2010–2020. Scientific Data 10:303 (2023). DOI: 10.1038/s41597-023-02213-z ⟨hal-04101350⟩