
Detecting offline influence through Twitter activity
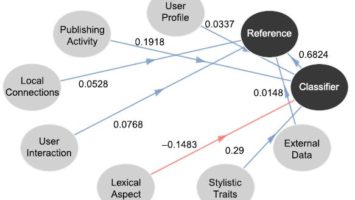
These scripts are meant to extract certain features from raw Twitter data describing Twitter users (tweets, profile info, as well as external data). Once the features are extracted, various forms of SVMs are trained, and logistic regressions are performed, to classify and rank the users. These operations are conducted on different subgroups of features. The details of the process are given in the below publications. The scripts were applied to the classification/ranking of Twitter users in terms of offline influence, based on the RepLab 2014 dataset.